

Alibaba presenta Qwen3‑Max, un modello linguistico di nuova generazione che punta a competere con le soluzioni di OpenAI, Google e Anthropic. La novità è nel mix tra scala (oltre 1 trilione di parametri, addestrati su 36 trilioni di token) e ingegneria d’efficienza basata su Mixture‑of‑Experts (MoE), con l’obiettivo dichiarato di migliorare velocità, stabilità e contesto lungo.
Qwen3-Max – Architettura e training
Qwen3‑Max adotta un’architettura MoE: invece di attivare l’intera rete a ogni passo, seleziona sottoinsiemi di “esperti” pertinenti. Questo approccio riduce i costi computazionali e massimizza l’efficienza rispetto a un puro scaling di parametri.
Alibaba segnala l’uso di una tecnica di bilanciamento chiamata global‑batch load balancing loss, progettata per mantenere stabile la convergenza durante il training su larga scala. Secondo l’azienda, la curva di loss è rimasta regolare senza necessità di riavvii o rimescolamenti dei dati a metà percorso, aspetto non scontato in addestramenti di questa dimensione.
Efficienza e affidabilità
La pipeline di addestramento introduce più novità orientate a throughput e resilienza dell’infrastruttura:
– PAI‑FlashMoE: ottimizzazione multi‑stadio di parallelismo che, rispetto a Qwen2.5‑Max‑Base, porta a un +30% di throughput in training. In pratica, meno settimane di addestramento a parità di risorse.
– ChunkFlow: strategia per contesti lunghi che, su input estesi, offre 3× il throughput rispetto alla sequence parallelism tradizionale. Il modello dichiara una finestra di contesto fino a 1 milione di token, posizionandosi nella fascia alta del mercato.
– SanityCheck e EasyCheckpoint: sistemi di affidabilità che, secondo Alibaba, riducono i tempi di inattività per guasti hardware a un quinto rispetto al ciclo Qwen2.5‑Max. Un punto cruciale quando si scala su cluster massivi.
Qwen3-Max – Prestazioni e benchmark
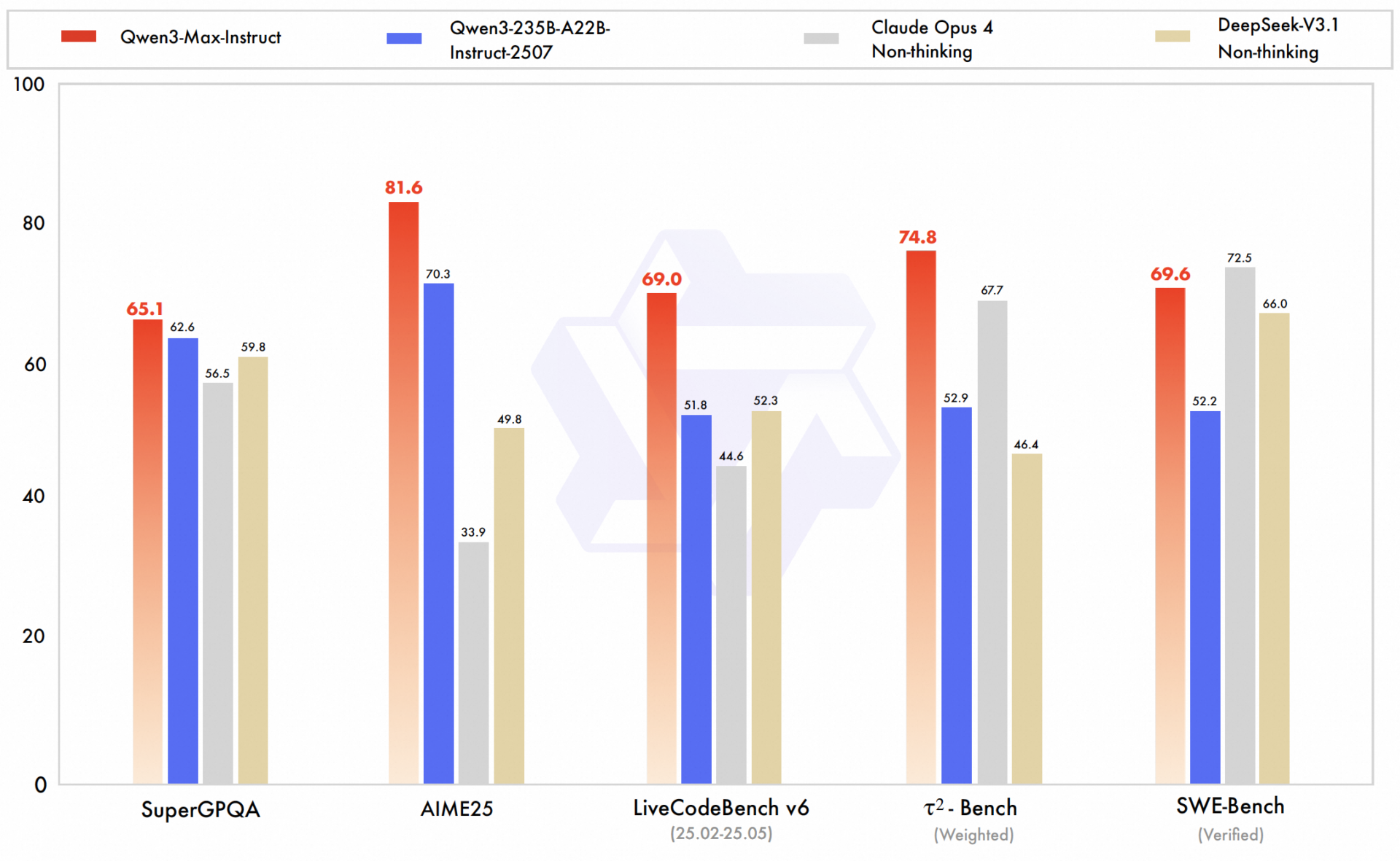
La versione utilizzabile, Qwen3‑Max‑Instruct, mostra risultati competitivi su più metriche pubbliche:
– LMArena: #3 in classifica complessiva, riportato davanti a una voce etichettata come “GPT‑5‑Chat”.
– SWE‑Bench Verified (coding reale su issue GitHub): 69,6, sopra DeepSeek V3.1 e in linea con Claude Opus 4.
– Tau2‑Bench (tool‑use): 74,8, superando Claude Opus 4 e DeepSeek V3.1 nei test citati.
Questi numeri indicano un focus concreto su programmazione, uso di strumenti esterni e robustezza nell’esecuzione di task realistici. Come sempre, le classifiche sono dinamiche e dipendono da setting e versioni: è prudente confrontare su workload interni prima di migrare stack produttivi.
Variante “Thinking” e ragionamento avanzato
Oltre all’Instruct, Alibaba sta addestrando Qwen3‑Max‑Thinking, variante orientata al ragionamento, con code interpreter integrato e capacità di tool‑use e calcolo parallelo in inferenza. Nei test preliminari riportati, ha raggiunto 100% su AIME 25 e HMMT (benchmark matematici severi). Dati promettenti, ma da confermare con verifiche indipendenti e suite più ampie, inclusi problemi rumorosi del mondo reale.
Multilingua e qualità delle risposte
Il progetto punta a una copertura multilingue con particolare forza in inglese e cinese. Secondo l’azienda, rispetto alle versioni precedenti, migliora in:
– Instruction following e coerenza logica;
– Ragionamento matematico e scientifico;
– Riduzione delle allucinazioni.
La capacità di gestire contesti molto lunghi (fino a 1M token) è un vantaggio per documenti tecnici, log e contratti. Resta però da valutare quanto la qualità decada all’aumentare della finestra: non tutti i token “contano” allo stesso modo e il retrieval mirato può restare preferibile in produzione.
Disponibilità, app e API
– Utenti finali: Qwen3‑Max‑Instruct è accessibile tramite l’app Qwen (iOS/Android) e via web. L’app utilizza di default Qwen3‑Max, con possibilità di switch manuale.
– Sviluppatori: integrazione via API su Alibaba Cloud Model Studio, utile per embedding in servizi, bot, agenti e pipeline di automazione. I dettagli di prezzo non sono stati comunicati nel materiale di riferimento e potrebbero dipendere dai piani di Alibaba Cloud.
Confronto interno: Instruct vs Thinking
Qwen3‑Max‑Instruct
Modello general‑purpose, addestrato per seguire istruzioni, scrivere codice, utilizzare strumenti e gestire contesti lunghi. È la variante disponibile oggi, con benchmark solidi su coding e tool‑use.
Qwen3‑Max‑Thinking
Variante focalizzata sul reasoning di alto livello con code interpreter nativo e design per l’uso intensivo di strumenti durante l’inferenza. I primi risultati su AIME e HMMT sono eccellenti, ma si tratta di un work‑in‑progress non ancora pubblicamente disponibile.
Cosa scegliere
– Per adozione immediata e carichi misti: Instruct è la scelta pragmatica.
– Per R&D su agenti autonomi e problemi formali complessi: la futura Thinking merita monitoraggio, con test indipendenti su dataset out‑of‑distribution.
Qwen3-Max – C’è competizione?
Qwen3‑Max entra nella stessa arena di GPT‑5 (quando disponibile), Gemini 2.5 Pro e Claude Opus 4. Il differenziatore di Alibaba è l’ingegneria: MoE aggressivo, throughput superiore in training (+30% segnalato), gestione affidabile dei cluster e contesto lungo fino a 1M token.
Sul fronte enterprise, restano variabili chiave: governance dei dati, costi di inferenza a contesto esteso, latenza e compliance transfrontaliera. Per gli ecosistemi già su Alibaba Cloud, l’integrazione via Model Studio riduce l’attrito; altrove sarà importante valutare lock‑in, disponibilità regionale e TCO.
Qwen3‑Max non è solo “più grande”: propone un pacchetto coerente di efficienza, affidabilità e contesto lungo, con metriche competitive su coding e tool‑use. Se le promesse su Thinking saranno confermate, Alibaba potrebbe ritagliarsi un ruolo forte negli agenti autonomi e nelle applicazioni tecniche ad alta complessità. Per ora, è un’alternativa credibile da mettere in proof‑of‑concept accanto ai modelli di OpenAI, Google e Anthropic.



